Executive Summary
Explore detailed research on Reinforcement. Americanbible Data Intelligence's dataset compiled from 10 authoritative feeds with 8 supporting visuals. This analysis also correlates with findings on REINFORCEMENT Definition & Meaning to provide a broader context. Unified with 14 parallel concepts to provide full context.
Reinforcement Complete Guide
Comprehensive intelligence analysis regarding Reinforcement based on the latest 2026 research dataset.
Reinforcement Overview and Information
Detailed research compilation on Reinforcement synthesized from verified 2026 sources.
Understanding Reinforcement
Expert insights into Reinforcement gathered through advanced data analysis in 2026.
Reinforcement Detailed Analysis
In-depth examination of Reinforcement utilizing cutting-edge research methodologies from 2026.
Visual Analysis
Data Feed: 8 Units
IMG_PRTCL_500 :: REINFORCEMENT

IMG_PRTCL_501 :: REINFORCEMENT

IMG_PRTCL_502 :: REINFORCEMENT
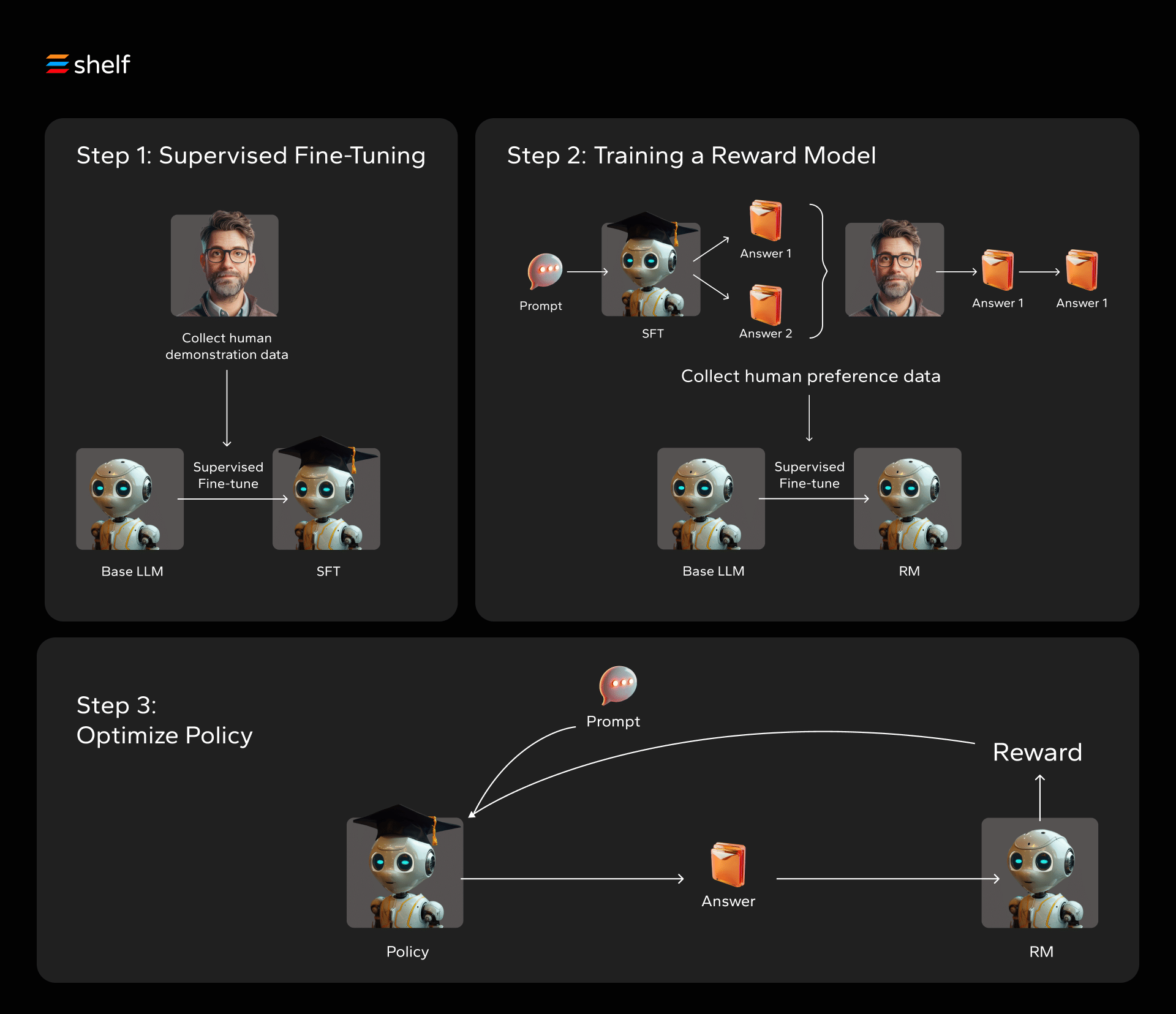
IMG_PRTCL_503 :: REINFORCEMENT

IMG_PRTCL_504 :: REINFORCEMENT

IMG_PRTCL_505 :: REINFORCEMENT
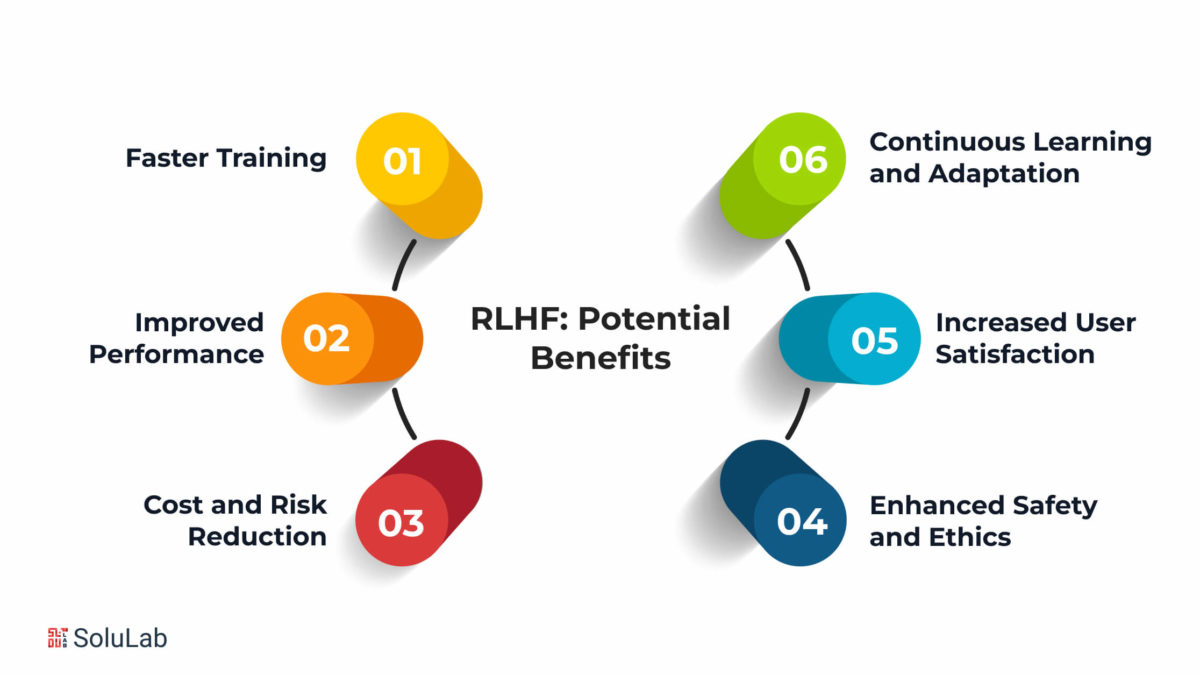
IMG_PRTCL_506 :: REINFORCEMENT
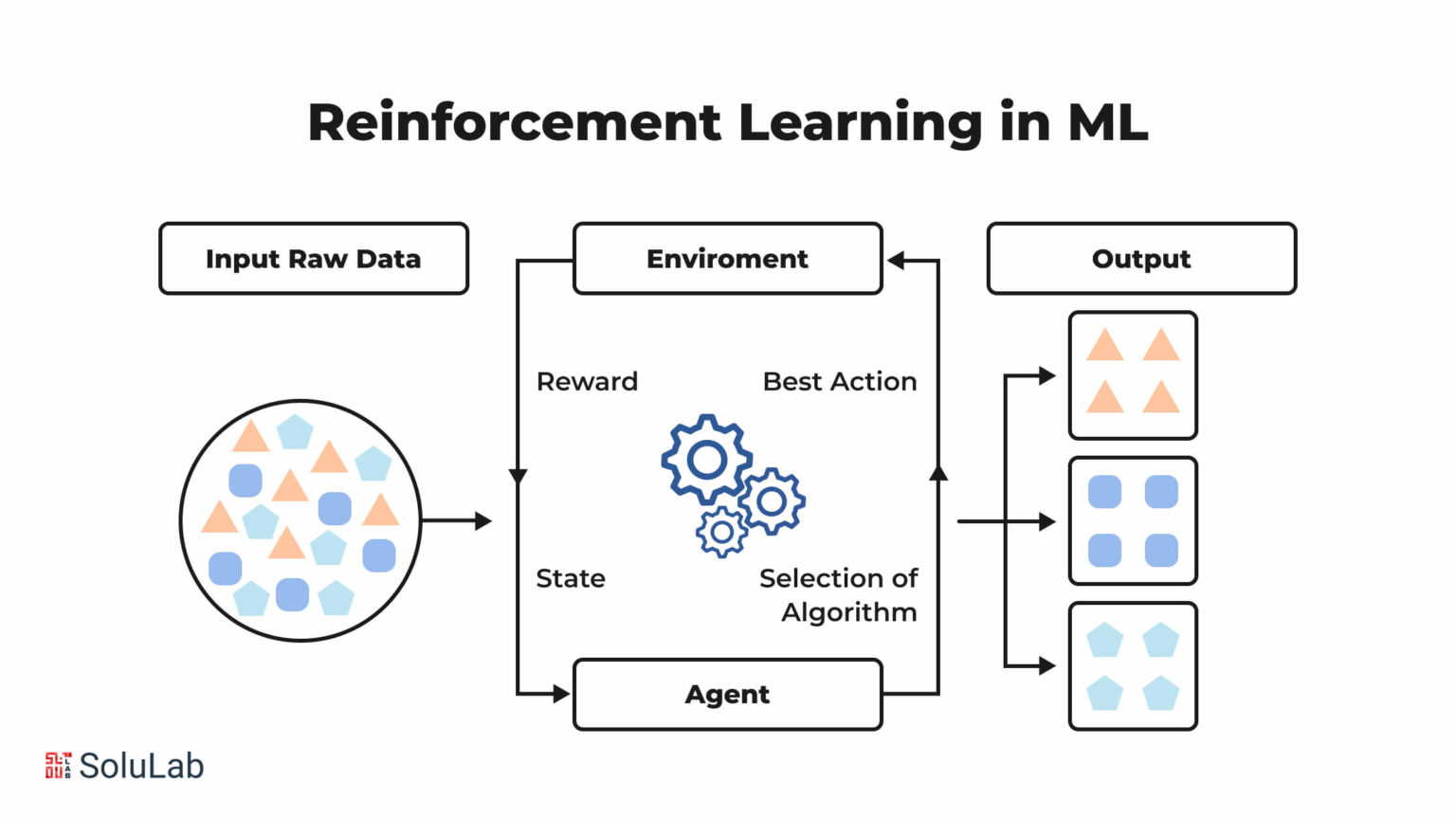
IMG_PRTCL_507 :: REINFORCEMENT
Key Findings & Research Synthesis
Review comprehensive data regarding reinforcement learning from human feedback rlhf. Our research module has processed 10 search snippets and 8 visual captures. It is linked to 14 similar themes to ensure completeness.
Helpful Intelligence?
Our neural framework utilizes your validation to refine future datasets for Reinforcement.